
Тестирование производительности вычислительного модуля Intel Xeon Phi
Дополнительные материалы по теме:
- Вычислительная система NVIDIA® Tesla™ - вычислительные решения на GPU
- Таблицы сравнительных характеристик процессоров: Intel Xeon E5-2400, Intel Xeon E5-2600
- Ссылки на разделы прайс-листа: Процессоры, Вычислительные модули
- Серверные конфигураторы
- Перечень моделей серверов и рабочих станций с поддержкой Intel Xeon Phi
Вычислительный модуль Intel Xeon Phi — математический сопроцессор с производительностью на операциях двойной точности до 1 TFLOPS — один триллион операций в секунду! Это в четыре раза быстрее рабочей станции на базе двух процессоров Intel Xeon E5-2650 (пиковая производительность 270 GFLOPS). В одну систему можно установить до 8-ми Intel Xeon Phi.

Вычислительный модуль Intel Xeon Phi построен на базе 64-битной архитектуры x86, поэтому для него не нужно переписывать имеющиеся программы, достаточно их просто перекомпилировать — в отличие от вычислительных модулей NVIDIA, основанных на архитектуре CUDA и требующих при программировании использования специализированных функций.
В этой статье мы расскажем о результатах тестирования производительности Intel Xeon Phi, а также обсудим некоторые вопросы параллельных вычислений, то есть таких задач, которые можно разбить на параллельные ветви или процессы, выполняющиеся одновременно.
Поясним несколько терминов, которые мы будем использовать в данной статье.
Число двойной точности с плавающей запятой — вид компьютерного представления числа в нормализованной форме в соответствии со стандартом IEEE 754. Такое число занимает в памяти компьютера 8 байт и записывается в виде мантиссы со знаком и показателя степени. Точность представления мантиссы 16 значащих цифр, диапазон числа от 10-308 до 10308.
FLOP — одна операция над числами двойной точности. Операции могут быть как простыми (например, арифметические операции сложения и умножения), так и более сложными: извлечение корня, вычисление логарифма, возведение в степень или определение значений тригонометрических функций. Максимальные показатели производительности достижимы на простых арифметических операциях.
FLOPS — число операций двойной точности, выполняемых за одну секунду.
В наших тестах мы использовали двухпроцессорную рабочую станцию Team Workstation P4000CR с двумя процессорами Intel Xeon E5-2650 с микроархитектурой Intel Sandy Bridge.
Процессор Intel Xeon E5-2650 имеет восемь физических ядер. Каждое ядро может выполнить за один процессорный такт 8 операций двойной точности. Поскольку штатная рабочая частота процессора равна 2 GHz, пиковая теоретическая производительность одного ядра составляет:
8 FLOP/такт * 2 GHz (тактов/секунду) = 16 GFLOP/секунду = 16 GFLOPS
Каким образом достигается такая производительность?
Полный цикл обработки ядром процессора одной машинной инструкции занимает более одного такта. Он включает следующие основные этапы: загрузка инструкции и данных, декодирование инструкции, выполнение инструкции и, наконец, запись результата. Это сильно упрощенная схема, а на самом деле обработка инструкции включает больше этапов и требует соответствующего количества процессорных тактов.
Процессор организован при принципу конвейера. Каждый такт на вход процессора подается очередная инструкция. Инструкции, которые уже находятся на конвейере, передаются на следующий этап. На выходе конвейера появляется результат обработанной инструкции.
Таким образом, одновременно на конвейере параллельно обрабатывается несколько инструкций со сдвигом на один такт. Благодаря конвейерной организации процессор фактически обеспечивает обработку одной инструкции за один такт.
Но каким образом процессор выполняет за такт не одну, а восемь операций?
Ядро процессора может использовать в качестве операнда четыре числа благодаря наличию 256-битных регистров. В одном регистре помещается четыре 64-битных числа двойной точности. Такой процессор называют суперскалярным или векторным, потому что операция выполняется не над числом, а над вектором. Эта возможность обеспечивается расширением набора процессорных команд Intel AVX (Advanced Vector eXtensions).
Ядро процессора имеет несколько специализированных блоков ALU (арифметико-логических устройств), которые выполняют вычисления различных типов. Операции сложения и умножения выполняются разными ALU, поэтому могут происходить одновременно. Наличие совмещенных инструкций сложения и умножения позволяет ядру выполнять за один такт до восьми операций над числами двойной точности.
Эта технология, когда вместо операций со скалярными операндами выполняются операции с векторами, называется векторизацией. "Векторизация" программы происходит автоматически на этапе компиляции. Эффективность векторизации можно повысить, оптимизируя исходный код программы.
Итак, ядро имеет пиковую производительность 16 GFLOPS. В нашей тестируемой рабочей станции с двумя 8-ядерными процессорами всего 16 ядер. Общая теоретическая производительность рабочей станции:
16 GFLOPS/ядро* 8 ядер/CPU * 2 CPU = 256 GFLOPS
Чтобы получить такую производительность для одной программы, необходимо разбить эту программу на 16 потоков, которые будут выполняться параллельно каждый на своем ядре. Поскольку потоки будут работать в системе с общей памятью, они могут при необходимости обмениваться данными через глобальные переменные программы, хранящиеся в этой памяти.
Для создания таких параллельных программ, работающих в системах с общей памятью, разработан стандарт OpenMP (Open Multi-Processing) — совокупность директив компилятора, библиотек и переменных окружения, предназначенных для программирования многопоточных приложений в многоядерных и многопроцессорных системах с общей памятью.
Примером программы, которую легко "распараллелить" в системе с общей памятью, может служить цикл, в котором результат вычислений на каждом следующем шаге не зависит от результатов вычислений на предыдущих шагах. Такой цикл можно разбить на несколько меньших циклов, каждый из которых будет исполняться отдельной параллельной ветвью программы.
Параллельный исполняемый код может быть создан компилятором автоматически. Также можно в явном виде указать участок программы, который нужно "распараллелить", добавив в исходный текст программы специальную директиву OpenMP — прагму. При помощи прагм можно создавать потоки, распределять между ними задания, управлять классами данных (общие или локальные), а также синхронизировать потоки, если они обмениваются данными в процессе вычислений.
Во многих случаях автоматическое добавление параллелизма в программу при помощи компилятора обеспечивает достаточно эффективный результат. При этом количество ветвей программы во время исполнения зависит от числа доступных процессорных ядер. На компьютере с одноядерным процессором программа будет выполняться последовательно, а на компьютере с двумя 8-ядерными процессорами будут выполняться 16 параллельных ветвей.
Параллельную задачу можно запустить и на узлах вычислительного кластера. В этом случае на узлах запускаются одинаковые копии программы — процессы. Каждый процесс при запуске получает уникальный номер процесса, который определяет роль своего узла в общей вычислительной работе.
Процессы на разных узлах не имеют доступа к оперативной памяти других узлов, поэтому не могут обмениваться данными через память, как это происходит в системах с общей памятью. Организация взаимодействия процессов в этом случае регламентируется стандартом MPI (Message Passing Interface — Интерфейс Передачи Сообщений), который описывает способы обмена сообщениями между параллельными процессами одной задачи в системах с распределенной памятью.
В качестве коммуникационной среды могут использоваться различные физические интерфейсы. В нашем тестировании для связи между узлами кластера использовалась сеть Gigabit Ethernet. Каждый узел подключался к сети по двум портам, объединенным в агрегированный канал по стандарту 802.3ad.
MPI-задачу можно выполнить и на одном компьютере. В этом случае на нем запускается одновременно несколько параллельных процессов, которые в качестве коммуникационной среды используют общую память компьютера, но при этом обмен данными происходит не через общие переменные программы, как в стандарте OpenMP, а через протокол обмена сообщениями MPI.
Вычислительный модуль Intel Xeon Phi 3120A (тестируемая модель) имеет 57 физических ядер, 6 GB оперативной памяти и работает на частоте 1100 MHz. Благодаря использованию 512-битных регистров каждое ядро Intel Xeon Phi выполняет до 16 операций двойной точности за один такт. Поэтому его теоретическая пиковая производительность составляет:
16 FLOP/такт * 1,1 GHz (тактов/секунду) * 57 ядер = 1003 GFLOP/сек = 1,003 TFLOPS
Технические характеристики Intel Xeon Phi 3120A:
- микроархитектура Many Integrated Core (MIC), ядро Knights Corner, техпроцесс 22 нм
- 57 вычислительных ядер, технология Hyper-Threading, 4 потока на ядро, 228 потоков
- разрядность данных 64 бита, 512-битные векторные регистры
- кэш-память 1-го уровня L1: 32 KB данные / 32 KB инструкции на ядро, латентность 1 такт
- кэш-память 2-го уровня L2: 512 KB на ядро, латентность 11 тактов
- 6 GB оперативной памяти GDDR5, 16-ти канальный контроллер памяти
- пиковая пропускная способность подсистемы памяти 352 GB/сек, эффективная 200 GB/сек
- хост-интерфейс PCIe 2.0 x16, пропускная способность 6 GB/сек в каждом направлении
- пиковая производительность на операциях с двойной точностью 1003 GFLOPS
- потребляемая мощность 300 W, активное охлаждение
Вычислительный модуль Intel Xeon Phi управляется собственной операционной системой на базе Linux, имеет виртуальный диск с файловой системой, локальную оперативную память объемом 6 GB, виртуальный сетевой интерфейс и IP-адрес. С точки зрения хоста (рабочей станции) он может рассматриваться как самостоятельный вычислительный узел.
Теоретически в одну систему можно установить до восьми вычислительных модулей Intel Xeon Phi, однако реально для существующих серверных платформ можно говорить максимум о четырех модулях. Ограничивающими факторами являются: число линий PCIe — для четырех модулей понадобится 64 линии из 80 имеющихся в двухпроцессорной системе; мощность системы питания — для четырех модулей необходимо суммарно 1200W; производительность системы охлаждения рабочей станции, рассчитанной на установку максимум четырех карт расширения с рассеиваемой тепловой мощностью 300 W каждая.
Вычислительный модуль Intel Xeon Phi предполагает различные модели использования.
Режим "Native"
В этом режиме вычислительный модуль Intel Xeon Phi выступает в роли самостоятельного компьютера.
Программа, которая будет выполняться на модуле, должна быть откомпилирована в исполняемый код, предназначенный для запуска только на модуле. Затем программа вместе с необходимыми динамическими библиотеками должна быть записана на виртуальный диск модуля (либо на общий сетевой диск модуля и хоста) и запущена с консоли модуля.
Следует иметь в виду, что при данной модели использования размер задачи ограничивается объемом собственной оперативной памяти модуля, который составляет 6 GB.
Режим гетерогенного кластера
Хост вместе с установленным в нем вычислительным модулем Intel Xeon Phi можно рассматривать как кластер из двух узлов. На таком кластере можно запустить как одну задачу, выполняющуюся параллельно на двух узлах, так и две разные задачи, каждая на своем узле. В свою очередь, несколько таких хостов можно объединить между собой в "большой" гетерогенный кластер, состоящий из узлов двух типов. На таком кластере можно выполнять одновременно несколько задач, выбирая для каждой задачи узлы подходящего типа.
Режим сопроцессора или "offload"
В этом режиме задача запускается на хосте, а на сопроцессоре выполняются лишь отдельные участки программы с высокой степень параллелизма, для которых выполнение на сопроцессоре более эффективно, чем на хосте.
В исходном коде такой программы эти участки помечаются специальными директивами, которые указывают компилятору, что данные участки должны быть откомпилированы для выполнения на сопроцессоре. Во время выполнения задачи эти части программы выгружаются ("offload") в сопроцессор и исполняются там.
В этот режиме размер задачи не ограничен размером локальной памяти вычислительного модуля. Мы выполняли тестирование производительности Intel Xeon Phi именно в этом режиме.
В нашем сравнительном тестировании производительности принимали участие следующие системы:
- Двухпроцессорная рабочая станция на базе Intel Xeon E5-2650, 128 GB DDR3-1600
- Кластер из четырех двухпроцессорных станций на базе Intel Xeon E5-2650, 32 GB DDR3-1600
- Двухпроцессорная рабочая станция на базе Intel Xeon E5-2650, 128 GB DDR3-1600 с установленным вычислительным модулем Intel Xeon Phi 3120A.
Тестирование проводилось в среде операционной системы Red Hut Enterprise Linux 6.3.
Для тестирования производительности мы использовали пакет High-Performance LINPACK — тест, который используется при составлении списка Top 500 Supercomputers.
Тест заключается в решении системы N линейных уравнений методом LU-разложения. В качестве исходных данных используется квадратная матрица коэффициентов размером N x N, которая заполняется при помощи генератора случайных чисел. В дальнейшем, мы будем использовать термин "размер задачи N", имея в виду матрицу коэффициентов размером N x N.
Выбор пакета HPL в качестве теста обусловлен, во-первых, его широкой известностью и доступностью, а также тем обстоятельством, что алгоритм вычислений хорошо "распараллеливается" и масштабируется. Наконец, сама по себе задача решения системы линейных уравнений часто встречается в разнообразных практических расчетах.
Вычисления производились с двойной точностью. Общее количество операций, которое необходимо выполнить в ходе теста, известно заранее и определяется по формуле: 2N3 / 3 + 2N2. Разделив полученное число на время выполнения теста, можно определить общую производительность системы.
Данный тест является "хорошей" параллельной задачей — исходную матрицу можно разбить на блоки, обработку которых выполняют отдельные параллельные ветви программы. В ходе расчетов параллельные потоки должны обмениваться данными для вычисления значений на границе блоков.
Мы провели тесты для нескольких размеров задачи N, соответствующих "стандартным" значениям объема оперативной памяти вычислительных систем:
| Объем оперативной памяти | 1 GB | 2 GB | 4 GB | 8 GB | 16 GB | 32 GB | 64 GB | 128 GB |
| Размер задачи (N) | 10000 | 15000 | 20000 | 29000 | 41000 | 58000 | 83000 | 117000 |
Размер задачи для каждого значения объема оперативной памяти выбирался так, чтобы таблица коэффициентов занимала не более 80% памяти (один элемент таблицы — число двойной точности с плавающей запятой — занимает 8 байт).
При увеличении размера задачи N общее количество вычислений растет пропорционально N в третьей степени, а количество обменов между параллельными процессами растет пропорционально N во второй степени (приблизительно). Таким образом, доля обменов в общем времени выполнения задачи снижается, а вычислений — увеличивается. Поскольку мы измеряем скорость вычислений, а не обменов, при увеличении размера задачи измеряемая производительность системы растет. Исключением является последовательная задача, которая не содержит операций обмена, поэтому для нее производительность от размера зависеть не должна.
Как говорилось выше, пиковая теоретическая производительность двухпроцессорной рабочей станции на базе Intel Xeon E5-2650 2 GHz должна составлять:
2 GHz * 8 FLOP/такт * 8 ядер * 2 CPU = 256 GFLOPS
Для измерения производительности в среде OpenMP мы сначала скомпилировали программу соответствующим образом. Задавая количество параллельных потоков посредством переменных окружения, мы провели измерения производительности для 1, 2, 4, 8 и 16 потоков для размеров задачи от 10000 до 117000. Результаты приведены на графике:
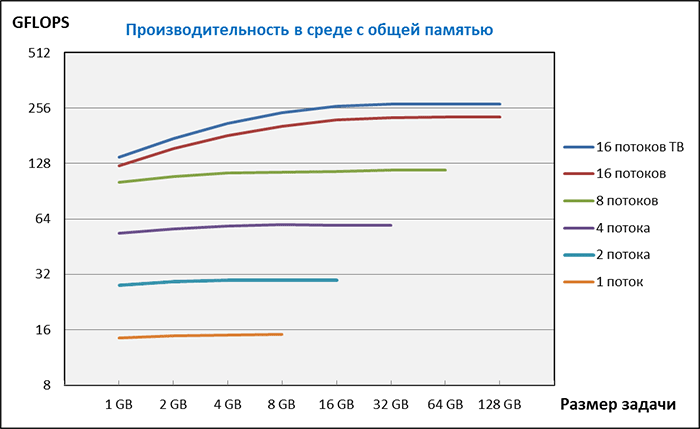
Измерения производились при отключенном режиме Turbo Boost. Intel Turbo Boost — это технология повышения рабочей частоты процессора при пиковой загрузке. Частота повышается автоматически при условии, что тепловыделение процессора не превышает установленный лимит. Когда загружено одно ядро, его частота может быть повышена существенно — до 2,8 GHz, когда загружено сразу несколько ядер, повышение частоты меньше. Чтобы режим Turbo Boost не искажал картину масштабирования производительности, мы его отключили. Впрочем, для 16 потоков мы измерили производительность и при включенном Turbo Boost, она составила 274 GFLOPS, что превышает теоретический предел для частоты 2 GHz — 256 GFLOPS. Из этого можно сделать вывод о том, что средняя частота ядер процессора во время теста с включенным Turbo Boost составляла 2,4 GHz:
274 GFLOPS / 230 GFLOPS (производительность при частоте 2 GHz) * 2 GHz ≈ 2,4 GHz
То есть режим Turbo Boost весьма эффективен даже при полной загрузке всех ядер.
Обратите внимание, что обе шкалы на графике логарифмические. Оказалось, что удвоение числа потоков практически удваивает производительность, которая на больших задачах во всех случаях близка к теоретическим пределам. При небольших размерах задачи производительность меньше из-за большей доли операций обмена в общем объеме операций.
Стоит сказать несколько слов об использовании технологии Hyper-Threading при параллельных расчетах. Данная технология, реализованная в процессорах Intel, позволяет выполнять на одном ядре два независимых потока вычислений. Операционная система при этом "видит" одно физическое ядро как два логических и сообщает о наличии на нашей рабочей станции 32 CPU. Однако, если использовать для параллельных потоков все 32 логических процессора, производительность будет ниже, поскольку два потока Hyper-Threading делят ресурсы одного физического ядра. Тем не менее, отключать режим Hyper-Threading в BIOS не следует, поскольку, как показало тестирование, это тоже снижает производительность. Необходимо при помощи переменных окружения организовать вычисления так, чтобы один поток задачи приходился на одно физическое ядро.
Таким образом, в системе с общей памятью, которой является наша рабочая станция в данном тестировании, организация параллельных вычислений средствами стандарта OpenMP позволяет получить практически линейный рост производительности при увеличении числа параллельных потоков. Так, для одного потока на одном ядре мы получили 15 GFLOPS, а на 16-ти ядрах — 230 GFLOPS, то есть потери составили около 4 %: 230 / (15 * 16) ≈ 0,96.
В отличие от среды OpenMP, когда запускается одна программа, которая в процессе выполнения разделяется на параллельные ветви (потоки), в среде MPI запускается несколько копий программы (процессов), которые тоже работают параллельно, но обмениваются данными не через переменные программы, хранящиеся в общей памяти, а посредством интерфейса передачи сообщений — MPI. Процессы можно запустить как на одной рабочей станции, так и на нескольких узлах, объединенных в кластер. В первом случае в качестве коммуникационной среды используется оперативная память рабочей станции, а во втором — сетевой интерфейс. На рабочей станции, как и в предыдущем примере, мы выполнили измерение для 1, 2, 4, 8 и 16 процессов, а на кластере из 4-х узлов — для 64 процессов.
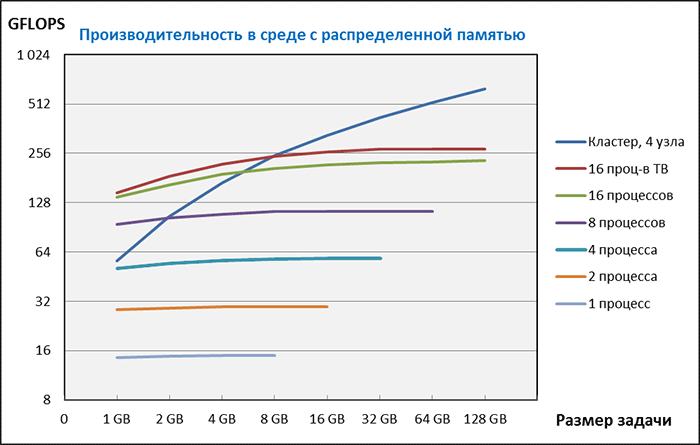
Оказалось, что для рабочей станции производительность в среде MPI практически не отличается от производительности в среде OpenMP. Поэтому, если производительности одной рабочей станции достаточно, задачу организации параллельных вычислений целесообразно решать средствами OpenMP, поскольку это сделать гораздо проще — распараллелить задачу можно автоматически на этапе компиляции. Использование средств MPI требует дополнительных усилий по доработке программы.
Производительность кластера сильно зависит от размера задачи. При небольшом размере задачи кластер уступает в производительности даже одному узлу, поскольку обмен данными между процессами сильно замедляет вычисления. По мере роста задачи относительная доля обменов уменьшается и суммарная производительность растет. Максимальная производительность для кластера в наших тестах составила 633 GFLOPS, что в 2,3 раза быстрее одного узла. По характеру кривой видно, что при увеличении размера задачи, производительность будет расти и при достаточно большом размере задачи может быть достаточно близка к пиковой теоретической производительности. "Сдвинуть" кривую вверх можно используя более быструю коммуникационную среду, с меньшей, нежели у Gigabit Ethernet, латентностью, например, InfiniBand.
Мы протестировали Intel Xeon Phi 3120A в режиме "Offload". В этом режиме задача запускается на рабочей станции, после чего основная расчетная часть программы выгружается в сопроцессор и выполняется там. Вычисления происходят с большим количеством параллельных потоков. Важно, что в режиме "Offload", в отличие от режима "Native", размер задачи не ограничен объемом оперативной памяти вычислительного модуля (6 GB). Мы смогли выполнить тестирование для задачи размером 64 GB, а вот задача на 128 GB все же вызвала переполнение памяти сопроцессора.
Результаты тестирования рабочей станции в среде OpenMP, кластера в среде MPI и вычислительного модуля в режиме "Offload" представлены на следующей диаграмме.
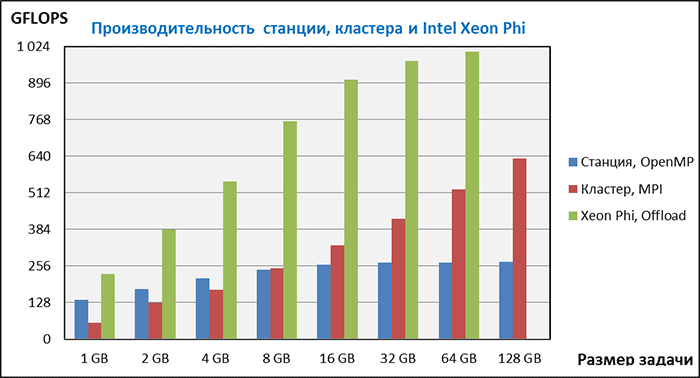
На всех размерах задачи вычислительный модуль продемонстрировал подавляющее преимущество и вчетверо превзошел показатели производительности рабочей станции. Таким образом, мы на собственном опыте смогли убедится в том, что компания Intel разработала действительно революционный продукт, который позволяет радикально повысить производительность параллельных вычислений без существенных затрат, поскольку стоимость вычислительного модуля составляет менее половины стоимости рабочей станции, которая использовалась в тестировании.
Итак, каковы необходимые условия для эффективных вычислений с использованием сопроцессора Intel Xeon Phi?
- Алгоритмы с большой "плотностью" регулярных вычислений и высокой степенью параллелизма. Согласно рекомендациям Intel для сопроцессора Xeon Phi подходят задачи с возможным числом параллельных ветвей не менее 100.
- Наличие мощной рабочей станции с установленным вычислительным модулем Intel Xeon Phi. Например, Team Workstation P4000CR.
- Операционная система, установленная на рабочую станцию, должна быть совместима с вычислительным модулем Intel Xeon Phi. Компания Intel ведет постоянную работу по расширению списка таких операционных систем.
- Компилятор с поддержкой набора инструкций для микроархитектуры MIC (Many Integrated Core). Например, компилятор Intel.
В данный момент мы предлагаем следующие модели серверов и рабочих станций с поддержкой Intel Xeon Phi:
| 1) Рабочая станция | Team P4000CR | – до 4-х сопроцессоров Intel Xeon Phi |
| 2) Сервер | Team P4000IP | – до 4-х сопроцессоров Intel Xeon Phi |
| 3) Сервер | Team P4000CO | – до 2-х сопроцессоров Intel Xeon Phi |
| 4) Сервер | Team R2000GZ | – до 2-х сопроцессоров Intel Xeon Phi |
| 5) Сервер | Team R2000BB | – до 2-х сопроцессоров Intel Xeon Phi |
| 6) Сервер | Team R2000LH | – до 2-х сопроцессоров Intel Xeon Phi |
| 7) Сервер | Team P4000SC | – 1 сопроцессор Intel Xeon Phi |
| 8) Сервер | Team R1000JP | – 1 сопроцессор Intel Xeon Phi |
Добавить сопроцессор Intel Xeon Phi в состав сервера или рабочей станции можно непосредственно в конфигураторе по приведенным ссылкам.
Спасибо.